author:徐振东
createTime:2022-05-16
updateTime:2022-05-16
2022-05-16: 培训结束
# 布隆过滤器
# 基本思想
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制 (opens new window)向量和一系列随机映射函数。布隆过滤器可以用于检索 (opens new window)一个元素是否在一个集合 (opens new window)中。
如果想判断一个元素是否存在于一个集合中,一般情况下,我们会想到将所有元素存储于集合中,然后再通过遍历比较的方式判断元素是否存在,它的时间复杂度为O(N),而且随着元素的增加,我们占用的内存空间也越来越大。而布隆过滤器的思想是将元素的原始值通过hash函数映射为二进制比特数组中的一个点位,当对应比特位的值置为1的时候,我们就认为该元素存在于集合中,反之则认为不存在。由于hash冲突的存在,当一个元素的hash值映射点位的值置为1,那么我们是没有办法证明该元素一定存在于集合中,所以一般在实际的布隆过滤器的实现中,一个元素会经过多个hash散列,只有多个hash散列所对应的比特位的值置为1,才认为该元素可能存在于集合中,该方式降低了误判的概率。

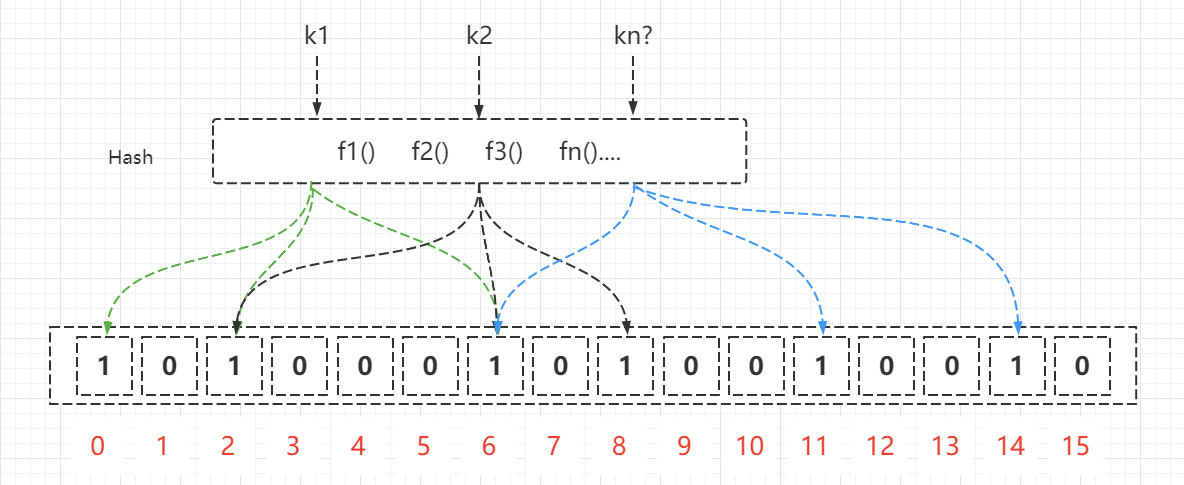
# 优点:
速度快
判断元素是否存在的时间复杂度由原先的 O(N) 降为 O(1)
节省内存空间
在节省内存方面的表现也是非常明显。考虑以下这个场景,假设有10w个key, 平均每个key占用1B的内存,这些key在内存中总共占用10w字节的空间。然而,如果是考虑布隆过滤器的话,在最极端没有Hash冲突的情况下,也仅需要10w个比特位就能存储所有的元素。
# 缺点:
- 存在一定的误判率
- 不支持删除元素
# 应用场景
- 缓存穿透
- 爬虫去重
# 代码使用
- 引入依赖,在谷歌的 guava 缓存工具包中有布隆过滤器的实现
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
模拟布隆过滤器的简单使用
// 创建布隆过滤器 // BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 100000); BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 100000, 0.01); // 模拟将已有元素存入过滤器 for (int i = 0; i < 100000; i++) { bloomFilter.put(i + ""); } // 统计误判率 for (int j = 0; j < 10; j++) { int count = 0; for (int i = 0; i < 1000; i++) { if (bloomFilter.mightContain("key" + i)) { count++; } } System.out.println("误判率为:" + (count * 100.0) / 1000 + "%"); }运行结果
误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4% 误判率为:1.4%
← 缓存穿透与缓存雪崩 Redis批量查询优化 →