author:韩皖
createTime:2023-03-21
updateTime:
培训结束时间:
# P003和P010优化心得分享
# MySQL优化
通常情况下,MySQL优化分为资源优化和性能优化,会根据实际情况,具体到某个项目去有针对性的优化,一切脱离了实际应用的优化都是伪优化, 所以根据不同应用的不同需求,很难做到大都通用,MySQL默认配置就相当于大多数情况下的最优情况。 根据P003、P010业务的特别,总结 mysql优化大概分为三点: 注:硬件(不做说明,外部条件)
# 1.MySQL服务器(辅助)
1.1 首先想到最大连接数,max_connections, 默认为151(可能版本不同,默认值会不同),一般情况下32G,8核集群, 链接瓶颈为300(普通硬盘)-700(固态硬盘)左右,之前有遇到把这个值设置为10000, 这个如果客户端服务程序配置最大连接数max-active不做限制的情况下,在并发量大的情况下,可能会造成MySQL服务无法正常运行, 导致客户端session无法正常连接mysql
1.2 maxallowedpacket,这个参数限制server接受的数据包大小。如果一次插入数据库中的数据太大的话就会失败, 因为P003和P010多处用到了批量操作,所以这个参数很重要,MySQL8.0默认64M,感觉也够用了,MySQL5.7默认4M,是有点小,根据情况配置。
1.3 groupconcatmax_len mysql8.0默认改配置为1024,在P010查询所有需要下发的设备信息时,想通过拼接字符串的方式, 一次拿到所有的设备的devAddr的信息,需要修改该配置,我们测试环境配置的为102400000即大约100MB
1.4 skip-log-bin 如果配置该参数则mysql的log-bin文件将不会记录,log-bin文件一般默认大概为存储数据的2倍左右,如果不关闭log-bin文件的写入, 则需要配置 expirelogsdays,即log-bin文件的存储天数(更正:后续涉及到集群或配置主从会导致无法使用,建议不要配置关闭, 属于取巧的方法,建议还是使用SSD来增加读写速度)
# 2.P003、P010服务
根据P003、P010服务实际情况,如上所述,脱离了实际生产的优化都是伪优化,我感觉这个是最重要的,而且也是最容易的, 因为我们自己的程序自己最了解,首先考虑几个问题: 1.我们为什么要去优化? 2.瓶颈在什么地方? 3.怎么去优化,优化的顺利是什么样的? 4.优化了是否对其他公用MySQL服务的程序影响很大? 如果没有问题1,我们就能return了,因为P010要接受P011大量的抄读返回数据并入库,P003要接受P010任务返回的大量数据解析后入库, 不优化我们效率低下,而且特别是P003是用户操作平台,MySQL的过度利用会影响用户的正常操作,大大降低用户的体验。 问题2、我们的瓶颈,只讲程序,硬件和服务器不是我们能左右的,我们考虑的是在恶劣环境下也能够好的生存下来,当然好的环境能更好的生活。 目前最大的瓶颈是流量,因为P010和P003都有大量的数据入库的操作,很多的insert、insertBatch,而不像门户网站一样的多的select, 比如并发的访问,可以用redis去缓冲,大的流量不会去访问mysql。 有了问题2,问题3怎么去优化: 优化的顺序:sql-》程序处理逻辑-》MySQL连接配置-》协作-》取舍,然后才是MySQL服务器配置,linux服务器配置
sql优化,我们根据监控平台(Druid)查到一些慢查询语句,进行sql的改造 改造前 ==》
select id id from tbl_a t1 left join on tbl_b t2 on t1.xid=t2.xid where t1.xid = ${5}改造后 ==》
select id id from (select * from tbl_a where xid = ${5}) t1 left join on tbl_b t2 on t1.xid=t2.xid where t1.xid = ${5}程序优化,比如首页
之前是串行的去查询MySQL,该之后用多个线程,同时查询mysql,返回前端,节省了n s。
分表 单表数据量过大,MySQL操作效率会下降。阿里Java开发手册上给的建议是,单表数据数量超过500w行或者容量超过2GB。推荐分库分表,所有我们抄读数据的日志数据,负荷曲线,日冻结,月冻结等等数据量大的表都做了分表处理,目前采用的是按日和按月来分表的规则,当然还有其他的根据业务数据的规则来进行分表,比如根据表地址,根据数据类型等。
批量操作,高并发下,每操作一次MySQL,都要有一次io、网络连接,很耗资源,改成批量操作后,减少了这部分的消耗。但是批量数据也不是越多越好,太多的话也不好,
我们做了个测试,虽然过大的批量确实是能整体减少操作的时间,但是单次时间会更加数据大小正比增加,如果越来越多的慢查询,MySQL过多的线程运转,返回后期效率会减低,而且大的数据包也会增加mysql 执行失败的概率,虽然这种情况很少,但是墨菲定律存在。所以P003暂时用的1-500,根据单条大小,来动态改变批量的条数,比如抄读一天的负荷曲线单条大小在8kb左右,但是抄读一天96个点的负荷曲线,单条数据在200kb以上,后续P010也将参考这种做法进行优化入库速度。
合理的规避流量,我们的瓶颈就是大流量,如果合理的规避流量是关键,其实我们需要的数据一定是要入库的,避免不了的,我们就insert就完了,但是有些数据我们已经存了不需要。再次insert,就要判断数据库里有没有这条记录,之前我们就收到数据就交给MySQL,让MySQL去判断(on duplicate key update),如果存在就不存或者修改,如果不存在就保存,这样虽然就节省了操作次数,但是我们的瓶颈就是大流量,一些不需要的流量我们就不必要全部发送到mysql了,我们修改后,只用了某个字段去mysql去查询记录是否存在,大大减少了数据流量。
MySQL 连接池的配置, 期初,在计划执行的时候,我们访问页面响应时间会很长,首先想到了mysql 查询的问题,因为任务返回数据的操作占满了mysql连接池的资源。
经过改造,解决了这个问题,我们把任务返回数据的操作放到一个池子,不管返回数据多么繁忙,不会影响池子之外的操作,设置MySQL的连接池大小大于线程池最大大小,这样就会保证池子之外,也就是正常页面接口去调用mysql。
数据量大的表或者多个表复杂查询,我们用了后台统计的做法,后台定时去做ETL(extract transform load),把有用的信息提炼出来保存到统计表表中,业务需要直接从统计表中查询汇总数据。
不管是MySQL或者其他的中间件,都需要注意的是团队协作性,不能只顾自己,也要考虑,如果自己这么做,会不会对其他服务有一些不好的影响,或者做一些改变,在不影响自己服务的前提下能不能对其他的服务调用有好的影响。
# Redis优化
无数大佬说过:谨慎使用缓存!
缓存失效是计算机科学两大难题之一,另一个我们在下面的业务也会提到,先卖个关子。
redis 号称10w+,但跟服务器配置有很大相关性,我们在 184服务器(32G内存)测试12w左右,一个配置很低的云机上经常2k 左右,差别有点大。
reids 访问和网络io关系很大,redis 用的单线程(严格也可能是多线程),因为cpu不是redis瓶颈,但是为啥有时候我们访问redis
还是有些慢的,其实大部分时间都浪费在了网络io上面,做了一个测试:
分别查询20000条数据,耗时多长时间。
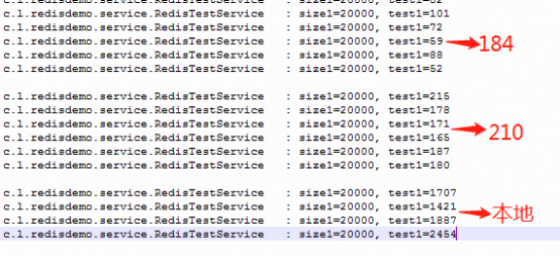
redis 放在了184服务器上,184 和 210 是互通的,可以清楚的看到分别在 184、 210、本地 访问速度,最大相差了40多倍, P003用的redis相对较少,优化的原则:
redis和服务最好放在同一个机房内或者同一个机架上,减少网络io
合理规划命名(计算机科学的第二个难题,命名),key值前缀使用Namespace
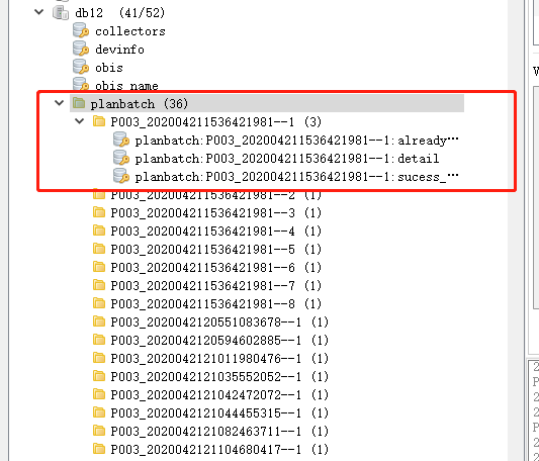
在使用Namespace之前查看redis的缓存是这样的,几十万上百万的key堆积在一起,无法快速定位查找到需要的信息

使用了Namespace之后,客户端工具会将相同Namespace的key合并在一起,看起来的效果是这样的,这样就能快速定位到某一抄表批次的数据。
- 第三方缓存服务(这里主要是Redis,项目早期还用到过Ehcache,Caffeine)
与本地JVM内存联合使用, 通常情况下,第三方缓存服务能够满足日常的访问需求。但如果需要追求更高的访问速度,热点资源可以在项项目运行时或使用前加载到JVM内存中。经测试对比第三方缓存较JVM内存在使用时,最高会有上千倍的速度差异,比如P010在每次服务启动时会将抄表指令数据加载到JVM内存中。
- 在数据量大的情况下,需要获取集合中的所有元素时,用SCAN命令替代一次性获取集合中的所有元素
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行。当客户端调用KEYS、SMEMBERS等命令一次性获取集合中的元素时将会阻塞服务器数秒之久影响后续命令的执行 SCAN 命令机器相关的SSCAN命令、HSCAN命令和ZSCAN命令都用于增量迭代集合元素。每次调用后只返回少量元素和一个新的游标,客户端下次调用时,使用这个返回的游标作为游标参数,以延续上次的迭代过程,它时间复杂度为 O(1)
- SCAN 命令用于迭代当前数据库中的主键
- SSCAN 命令用于迭代集合键中的元素
- HSCAN 命令用于迭代哈希键中的键值对
- ZSCAN 命令由于迭代有序集合键中的元素
由于补抄机制和超时机制的存在,P010必须要具备实时获取某一计划批次哪些电表已经抄表成功,哪些电表没有返回抄表结果的能力。之前的实现逻辑是在redis创建三个key,分别存储需要抄表的表devId,多个devId通过逗号隔开(String结构)、抄表成功的电表devId(List结构)、已返回抄表结果的表devId(List结构),最后通过key之间做减法得到需要的结果; 现在的实现逻辑是计划下发前,假定所有的电表都不返回结果,所有的电表都抄表失败,将所有电表的表devId分别存入两个set结构中,假定两个key分别为【抄表失败的电表devIds】和【抄表无返回结果的devIds】,然后每收到一条抄表结果记录,便将当前记录的devId从【抄表无返回结果的devIds】移除,若该记录抄表成功,继续从【抄表失败的电表devIds】移除当前设备,由于使用的是set结构,所以这两个移除步骤的时间复杂度都为O(1)。
- Redis应用 - 位图 能大量节省内存
位图通过最小的单位bit来进行0和1的设置,但它并不是一种特殊的数据结构,其本质上是二进制字符串,也可以看做byte数组。客户端可以通过setbit/getbit命令设置指定索引位的标志。如在P010计划抄表中有一个业务逻辑是要确保在一个抄表周期内,一块电表只能收到一条抄表数据:之前的处理方式是采用setnx命令,每一块电表都有一个key,所以抄读60w块电表就有60w个key,要是有任务堆积重叠,动辄会有上百万个key存在,浪费大量内存且影响IO;而如果使用位图的话只要1个key就可以搞定,实现逻辑为计划下发时给每一块电表一个编号,而收到这块电表的数据时,只要将位图索引等于电表编号的那个位置设置为1即可,抄完60w块电表最后仅占用了60w / 8 / 1024 = 73.23KB 的内存。
尽量减少和redis的交互次数:交互的越多越耗时,尽量使用批量命令。
比如在P010中的应用场景,在下发任务时获取设备的基础信息,通过批量的方式获取,大幅增加了下发速度;另一个场景,在收到抄读数据返回时,更新统计数据,更新成功的设备号列表,更新返回的设备号列表等操作都优化为批量修改的方式。